
In 2025, Zenlayer Elastic Compute (ZEC) rolled out a new generation of servers built on AMD's Zen4 platform, broadening the instance shapes we can offer. The workhorse CPU is the EPYC 9654. Zen4 lets us pack substantially more cores into every rack, and that in turn lets us keep up with the relentless compute demand coming from ZEC's edge footprint.
But raw cores are only half of the story. As we refreshed the hardware, we also took the opportunity to revisit a bottleneck that had been quietly shaping the user experience on our previous-generation EPYC 7H12 fleet: the host network.
This post walks through what we found, the trade-offs we weighed, and the NUMA-aware network architecture we ultimately shipped with the new platform.
Where the Old Architecture Hurt
Our first-generation network design was conventional and, on paper, sensible:
- Two dual-port NICs (ConnectX-5) per host
- Each NIC pinned to a separate NUMA node (NPS=2)
- Both ports of each NIC bonded together
- One NIC dedicated to the VPC network, the other to storage
- SR-IOV enabled on the VPC NIC, with multi-queue VFs handed off to guest VMs

In bandwidth-bound workloads it performed exactly as designed. The trouble started when we looked at the workloads our customers actually ran. A large share of ZEC VMs are network-heavy — reverse proxies, API gateways, game servers, real-time pipelines — and what they stress is packets per second, not gigabits per second. On those hosts we kept seeing the same pattern: plenty of idle CPU, plenty of headroom on the wire, and yet the network had already tapped out.
In production, three issues consistently showed up:
- The host couldn't feed the NIC. Bandwidth-bound workloads ran fine, but under high-concurrency small-packet traffic with many VFs and queues, CX5 PPS flatlined well short of its rated performance. We never ran a surgical root-cause analysis, but Zen2's on-package fabric and memory I/O path were the plausible suspects — the host simply couldn't drain packets from the NIC fast enough, and this was the dominant cap on per-host network capacity.
- The storage NIC sat half-idle. The storage path is simple to drive and sustained heavy disk I/O is rare in our production mix, so the dedicated storage NIC was chronically over-provisioned — host network resources were used very unevenly across the two NICs.
NUMA affinity worked against the network. VMs are NUMA-affine by default, which keeps guest memory access local and predictable. But the VPC NIC was wired to exactly one node, so roughly half the fleet paid a cross-node tax on every packet — and that extra memory-access latency capped network performance for those VMs.

The extra hop isn't a fixed cost — it gets worse as the fabric gets busier, because the same internal link has to carry every cross-node packet on the host:

Moving to Zen4 plus ConnectX-6 effectively erased problem #1 for free. Problems #2 and #3 are architectural rather than silicon, and would follow us into the new generation unless we did something about them.
The Option We Didn't Take
The most direct fix for the NUMA-affinity imbalance is almost embarrassingly simple:
- Add a third NIC, so that every NUMA node has its own dedicated VPC NIC.
- Teach the scheduler to allocate VM network resources with the same NUMA affinity it already applies to cores and memory.
This would dissolve the cross-node traffic problem entirely. But when we walked it through, three concerns pushed back:
- A three-NIC layout is topologically asymmetric and makes capacity planning and failure reasoning meaningfully harder.
- With SR-IOV in the picture, VFs are bound to their parent PF and cannot be link-aggregated across physical NICs — we'd have to give up bonding anyway.
- The extra NIC is not free: BOM cost, top-of-rack switch ports, cabling, and operational surface area all go up.
On balance, it wasn't worth it. We wanted the NUMA win without the third NIC.
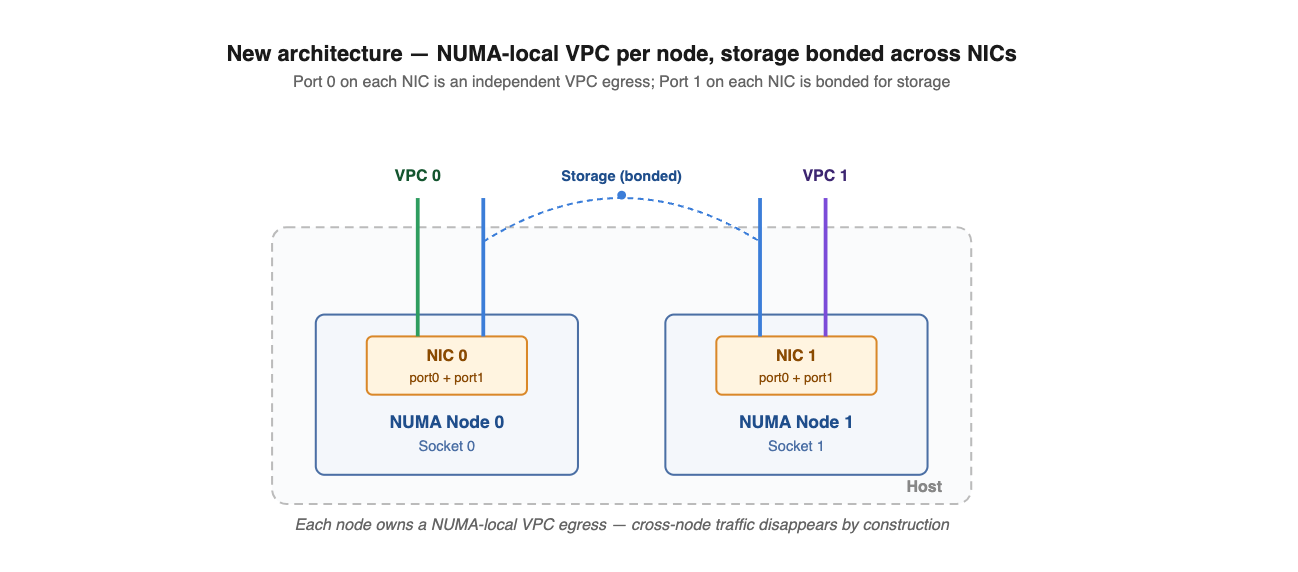
The New Architecture
The design we shipped keeps the two-NIC layout but rethinks how the four ports are used:
- Two dual-port ConnectX-6 NICs per host
- Each NIC pinned to its own NUMA node (NPS=2)
- Port 0 of each NIC carries VPC traffic — unbonded, used independently
- Port 1 of each NIC carries storage traffic — bonded, as before

On the software and scheduling side, three things change:
- The VPC network moves from a single default egress to a multi-egress model, with an independent egress per NUMA node.
- The scheduler guarantees that any SR-IOV VF assigned to a VM is NUMA-affine to that VM's cores and memory.
- The egress path for
virtio-netemulated NICs is likewise kept NUMA-local.
With strict NUMA affinity enforced end-to-end, VPC traffic stays on the node it originated from. The cross-node penalty disappears, and the "wasted" storage NIC quietly becomes a first-class VPC egress on the other half of the host. Two problems, one structural change.
The payoff showed up clearly in the numbers. Bandwidth under the new architecture matches the old, while PPS roughly doubles — right in line with what the design predicted:
| Architecture | PPS |
|---|---|
| Old architecture (CX5) | 2M |
| Old architecture (CX6) | 18M |
| New architecture (CX6) | 40M |
The jump from 2M → 18M is the Zen2 → Zen4 / CX5 → CX6 silicon story. The jump from 18M → 40M is the architecture story — and it's the one we actually designed for.
Paying Back the Availability Debt
Unbonding the VPC ports isn't free. Link-layer bonding gave us transparent failover against a dead port, a bad cable, or a flaky switch; removing it means every one of those faults is now visible to the host. To close the gap, we pushed the failover logic up the stack into application-layer traffic scheduling: every VPC link is health-checked continuously, and on a single-link failure traffic is automatically steered onto the surviving link.
The full failure matrix, before and after that compensation:
| Failure mode | Old arch | New arch (raw) | New arch (+ failover) |
|---|---|---|---|
| Single port failure | ✓ | ✗ | ✓ |
| Single cable failure | ✓ | ✗ | ✓ |
| Single switch failure | ✓ | ✗ | ✓ |
| Single NIC failure (VPC) | ✗ | ◐ 50% survives | ✓ |
| Single NIC failure (storage) | ✗ | ✗ | ✓ |
✓ tolerated · ✗ not tolerated · ◐ partially tolerated
You can think of this as application-layer "pseudo-bonding." It's not quite a drop-in replacement for link-layer bonding:
- Failover is slightly slower than kernel-level bond failover.
- Most of the switchover cost is in re-attaching SR-IOV devices, not in the control plane itself.
In production, both have proved to be comfortably within our SLOs.
Does Sharing a NIC Hurt Storage?
VPC and storage now share physical NICs. Port-level isolation holds under nominal conditions, but "nominal" isn't enough — we needed to know what happens when the VPC side gets greedy. So we ran a joint stress test: fixed storage workload, VPC load swept from 20% to 100%.
Each cell below shows throughput / latency (ms) — IOPS for the 4K rows, bandwidth for the 1M and 4M rows.
| VPC load | 4K read | 4K write | 1M read | 1M write | 4M read | 4M write | Fluctuation |
|---|---|---|---|---|---|---|---|
| 20% | 156K / 1.8 | 67K / 3.0 | 2.93G / 12 | 2.93G / 30 | 2.93G / 64 | 2.93G / 94 | 0% |
| 80% | 155K / 1.9 | 67K / 2.9 | 2.98G / 12 | 2.98G / 30 | 2.88G / 64 | 2.88G / 94 | 0% |
| 90% | 156K / 1.9 | 67K / 2.8 | 2.95G / 12 | 2.95G / 30 | 2.85G / 66 | 2.85G / 96 | 0% |
| 95% | 155K / 1.9 | 66K / 3.0 | 2.95G / 13 | 2.95G / 30 | 2.80G / 68 | 2.80G / 97 | 0% |
| 100% | 155K / 1.9 | 66K / 3.0 | 2.80G / 13 | 2.80G / 31 | 2.70G / 70 | 2.70G / 100 | −5% |
Two clean conclusions:
- At 100% VPC saturation, storage throughput drops by roughly 20% on the large-block paths.
- At 95% and below, storage is effectively untouched.
So we leave a little headroom on the table. A global rate-limit caps VPC peak utilization at 90%, which costs us a small slice of theoretical VPC capacity and buys us a storage SLO that doesn't wobble when a noisy neighbor shows up. That's a trade we're happy to make.
Looking Back
The interesting thing about this project, in hindsight, is how much of the work was not really about the NIC. The NIC wasn't blameless — moving from CX5 to CX6 obviously mattered — but on both the old platform and the new one, the dominant factor was something further upstream: how data moves through the system. On the new platform, most of the work was making sure the scheduler, the NIC layout, and the NUMA topology all agreed about where a given flow should live so that data didn't have to move further than necessary.
That framing isn't unique to host networking. It's the same story in GPU inference today: the matrix units have raced far ahead of the memory and interconnect feeding them, and most of the interesting work is keeping tensors close to the compute that needs them. The units doing the work are rarely what runs out first — the path the data takes to reach them is.
That's also why we care about getting this right. Built for production is one of ZEC's pillars, and in practice it means work like this: chasing the bottleneck to wherever it actually lives, even when that's two hops away from the component with the label on it, so that workloads running on ZEC get a stable and predictable environment — and so we have the evidence to stand behind it. NUMA-awareness is one instance of that discipline. It won't be the last.